Apache Phoenix ir salīdzinoši jauns atvērtā koda Java projekts, kas nodrošina JDBC draiveri un SQL piekļuvi Hadoop NoSQL datu bāzei: HBase. Tas tika izveidots kā Salesforce iekšējais projekts, kas tika atvērts no GitHub, un 2014. gada maijā kļuva par augstākā līmeņa Apache projektu. Ja jums ir spēcīgas SQL programmēšanas prasmes un vēlaties tos izmantot ar jaudīgu NoSQL datu bāzi, Phoenix varētu būt tieši tas, ko meklējat!
Šajā apmācībā Java izstrādātāji tiek iepazīstināti ar Apache Phoenix. Tā kā Phoenix darbojas virs HBase, mēs sāksim ar HBase pārskatu un to, kā tas atšķiras no relāciju datu bāzēm. Jūs uzzināsiet, kā Phoenix pārvar plaisu starp SQL un NoSQL un kā tas ir optimizēts, lai efektīvi mijiedarbotos ar HBase. Ņemot vērā šos pamatus, mēs atlikušo raksta daļu pavadīsim, mācoties, kā strādāt ar Fēniksu. Jūs izveidosiet un integrēsit HBase un Phoenix, izveidosiet Java lietojumprogrammu, kas savienosies ar HBase caur Phoenix, un jūs uzrakstīsit savu pirmo tabulu, ievietosiet datus un palaidīsit tajā dažus vaicājumus.
Četru veidu NoSQL datu krātuve
Interesanti (un nedaudz ironiski), ka NoSQL datu krātuves tiek iedalītas pēc pazīmes, kuras tiem trūkst, proti, SQL. NoSQL datu krātuvēs ir četras vispārīgas garšas:
- Atslēgu / vērtību veikali piesaistiet noteiktu atslēgu vērtībai, kas var būt dokuments, masīvs vai vienkāršs tips. Atslēgu / vērtību krājumu piemēri ir Memcached, Redis un Riak.
- Dokumentu veikali pārvaldīt dokumentus, kas parasti ir bez shēmas struktūras, piemēram, JSON, kas var būt patvaļīgi sarežģīti. Lielākā daļa dokumentu veikalu nodrošina primāro indeksu, kā arī sekundāro indeksu un sarežģītu vaicājumu atbalstu. Dokumentu veikalu piemēri ir MongoDB un CouchBase.
- Grafiku datu bāzes galvenokārt koncentrēties uz attiecībām starp objektiem, kuros dati tiek glabāti mezglos, un attiecībām starp mezgliem. Grafu datu bāzes piemērs ir Neo4j.
- Uz kolonnām orientētas datu bāzes glabājiet datus kā datu kolonnu sadaļas, nevis kā datu rindas. HBase ir uz kolonnām orientēta datu bāze, tāpat kā Kasandra.
HBase: grunts
Apache HBase ir NoSQL datu bāze, kas darbojas virs Hadoop kā izplatīts un mērogojams lielo datu krājums. HBase ir uz kolonnām orientēta datu bāze, kas izmanto Hadoop Distributed File System (HDFS) un Hadoop's MapReduce programmēšanas paradigmas izplatītās apstrādes iespējas. Tas bija paredzēts, lai mitinātu lielas tabulas ar miljardiem rindu un potenciāli miljoniem kolonnu, kas visas šķērso preču aparatūras kopu.
Apache HBase apvieno Hadoop spēku un mērogojamību ar iespēju vaicāt par atsevišķiem ierakstiem un izpildīt MapReduce procesus.
Papildus no Hadoop mantotajām iespējām HBase ir pati par sevi spēcīga datu bāze: tā reāllaika vaicājumus apvieno ar atslēgu / vērtību krātuves ātrumu, stabilu tabulu skenēšanas stratēģiju ātrai ierakstu atrašanai un atbalsta pakešu apstrādi izmantojot MapReduce. Kā tāds Apache HBase apvieno Hadoop spēku un mērogojamību ar spēju vaicāt atsevišķus ierakstus un izpildīt MapReduce procesus.
HBase datu modelis
HBase organizē datus atšķirīgi no tradicionālajām relāciju datu bāzēm, atbalstot četrdimensiju datu modeli, kurā katru "šūnu" attēlo četras koordinātas:
- Rindas taustiņš: Katrai rindai ir unikāls rindas taustiņš to iekšēji attēlo baitu masīvs, bet tam nav oficiāla datu veida.
- Kolonnu ģimene: Rindā esošie dati ir sadalīti kolonnu ģimenes; katrai rindai ir viena un tā pati kolonnu saime, bet katrai kolonnu grupai nav jāuztur tas pats kolonnu kvalifikatoru kopums. Jūs varat iedomāties kolonnu saimes kā līdzīgas tabulām relāciju datu bāzē.
- Kolonnu kvalifikācija: Tie ir līdzīgi kolonnām relāciju datu bāzē.
- Versija: Katrā kolonnā var būt konfigurējams skaits versijas. Ja pieprasāt kolonnā esošos datus, nenorādot versiju, tiek saņemta jaunākā versija, bet vecākas versijas varat pieprasīt, norādot versijas numuru.
1. attēlā parādīts, kā šīs četras dimensiju koordinātas ir saistītas.
 Stīvens Heinss
Stīvens Heinss 1. attēlā redzamais modelis parāda, ka rindu veido rindas atslēga un patvaļīgs kolonnu grupu skaits. Katra rindas atslēga ir saistīta ar "rindu tabulās" kolekciju, katrai no tām ir savas kolonnas. Kaut arī katrai tabulai jābūt, tabulu kolonnas dažādās rindās var atšķirties. Katrai kolonnu saimei ir kolonnu kopa, un katrai kolonnai ir versiju kopa, kas atbilst faktiskajiem datiem rindā.
Ja mēs modelētu personu, rindas atslēga varētu būt personas sociālās apdrošināšanas numurs (lai tos unikāli identificētu), un mums varētu būt kolonnu grupas, piemēram, adrese, nodarbinātība, izglītība un tā tālāk. Iekšpusē adrese kolonnu saime mums varētu būt ielas, pilsētas, štata un pasta indeksa kolonnas, un katra versija var atbilst vietai, kur persona dzīvoja attiecīgajā brīdī. Jaunākajā versijā var būt iekļauta pilsēta “Losandželosa”, savukārt iepriekšējā versijā - “Ņujorka”. Šo modeļa piemēru var redzēt 2. attēlā.
 Stīvens Heinss
Stīvens Heinss Kopumā HBase ir uz kolonnām orientēta datu bāze, kas atspoguļo datus četru dimensiju modelī. Tas ir veidots virs Hadoop izplatītās failu sistēmas (HDFS), kas sadala datus potenciāli tūkstošiem preču mašīnu. Izstrādātāji, kas izmanto HBase, var tieši piekļūt datiem, piekļūstot rindas atslēgai, skenējot visā rindu atslēgu diapazonā vai izmantojot pakešapstrādi, izmantojot MapReduce.
Pamatu izpēte
Jums var būt vai nav pazīstami slavenie (geeks) lielo datu baltie dokumenti. Laikā no 2003. līdz 2006. gadam publicējis Google Research, šajos baltajos dokumentos tika parādīti trīs Hadoop ekosistēmas pīlāru pētījumi, kā mēs to zinām:
- Google failu sistēma (GFS): Hadoop izplatītā failu sistēma (HDFS) ir GFS atvērtā koda ieviešana, un tā nosaka, kā dati tiek izplatīti preču mašīnu kopā.
- MapReduce: funkcionāla programmēšanas paradigma, lai analizētu datus, kas ir sadalīti pa HDFS kopu.
- Bigtable: sadalīta glabāšanas sistēma strukturētu datu pārvaldīšanai, kas paredzēta mērogošanai ļoti lielos izmēros - datu petabaiti, izmantojot tūkstošiem preču mašīnu. HBase ir Bigtable atvērtā pirmkoda ieviešana.
NoSQL trūkuma novēršana: Apache Phoenix
Apache Phoenix ir augstākā līmeņa Apache projekts, kas nodrošina SQL saskarni HBase, kartējot HBase modeļus relāciju datu bāzes pasaulē. Protams, HBase nodrošina savu API un apvalku tādu funkciju veikšanai kā skenēšana, iegūšana, ievietošana, saraksts un tā tālāk, taču vairāk izstrādātāju pārzina SQL nekā NoSQL. Phoenix mērķis ir nodrošināt HBase kopīgi saprotamu saskarni.
Runājot par funkcijām, Phoenix rīkojas šādi:
- Nodrošina JDBC draiveri mijiedarbībai ar HBase.
- Atbalsta lielu daļu ANSI SQL standarta.
- Atbalsta DDL darbības, piemēram, CREATE TABLE, DROP TABLE un ALTER TABLE.
- Atbalsta tādas DML darbības kā UPSERT un DELETE.
- Apkopo SQL vaicājumus vietējās HBase skenēs un pēc tam atbildi uz JDBC ResultSets.
- Atbalsta versijas shēmas.
Papildus tam, ka tiek atbalstīts plašs SQL darbību kopums, Phoenix darbojas arī ļoti labi. Tas analizē SQL vaicājumus, sadala tos vairākos HBase skenējumos un palaiž tos paralēli, MapReduce procesu vietā izmantojot vietējo API.
Phoenix izmanto divas stratēģijas - līdzprocesorus un pielāgotus filtrus -, lai aprēķinus tuvinātu datiem:
- Līdzstrādnieki veikt operācijas serverī, kas samazina klienta / servera datu pārsūtīšanu.
- Pielāgoti filtri samazināt no servera vaicājuma atbildē atgriezto datu daudzumu, kas vēl vairāk samazina pārsūtīto datu daudzumu. Pielāgotie filtri tiek izmantoti vairākos veidos:
- Izpildot vaicājumu, pielāgotu filtru var izmantot, lai identificētu tikai būtiskās kolonnu grupas, kas nepieciešamas, lai apmierinātu meklēšanu.
- A izlaist skenēšanas filtru izmanto HBase SEEK_NEXT_USING_HINT, lai ātri pārvietotos no viena ieraksta uz nākamo, kas paātrina punktu vaicājumus.
- Pielāgots filtrs var "sālīt datus", kas nozīmē, ka rindas atslēgas sākumā tas pievieno hash baitu, lai tas varētu ātri atrast ierakstus.
Rezumējot, Phoenix izmanto tiešu piekļuvi HBase API, kopprocesoriem un pielāgotajiem filtriem, lai sniegtu jums milisekunžu līmeņa veiktspēju mazām datu kopām un otrā līmeņa veiktspēju humongous. Galvenokārt, Fēnikss atklāj šīs iespējas izstrādātājiem, izmantojot pazīstamu JDBC un SQL saskarni.
Sāciet ar Phoenix
Lai izmantotu Phoenix, jums ir jālejupielādē un jāinstalē gan HBase, gan Phoenix. Phoenix lejupielādes lapu (un piezīmes par HBase saderību) varat atrast šeit.
Lejupielādēt un iestatīt
Šīs rakstīšanas laikā jaunākā Phoenix versija ir 4.6.0, un lejupielādes lapā ir lasāms, ka 4.x ir saderīgs ar HBase versiju 0.98.1+. Piemēram, es lejupielādēju jaunāko Phoenix versiju, kas ir konfigurēta darbam ar HBase 1.1. To var atrast mapē: fēnikss-4.6.0-HBase-1.1 /.
Lūk, iestatīšana:
- Lejupielādējiet un atspiest šo arhīvu un pēc tam izmantojiet vienu no šeit ieteiktajām spoguļlapām, lai lejupielādētu HBase. Piemēram, es izvēlējos spoguli, pārlūkoju mapi 1.1.2 un lejupielādēju
hbase-1.1.2-bin.tar.gz. - Atšifrējiet šo failu un izveidojiet
HBASE_HOMEvides mainīgais, kas uz to norāda; piemēram, es savam pievienoju sekojošo~ / .bash_profilefails (Mac datorā):eksportēt HBASE_HOME = / Lietotāji / shaines / Lejupielādes / hbase-1.1.2.
Integrējiet Phoenix ar HBase
Phoenix integrēšanas HBase process ir vienkāršs:
- Kopējiet šo failu no Phoenix saknes direktorija HBase
libdirektorijs:phoenix-4.6.0-HBase-1.1-server.jar. - Sāciet HBase, izpildot šo HBase skriptu
atkritumu tvertnedirektorijs:./start-hbase.sh. - Kad darbojas HBase, pārbaudiet, vai Phoenix darbojas, izpildot SQLLine konsoli, izpildot šādu komandu no Phoenix's
atkritumu tvertnedirektorijs:./sqlline.py localhost.
SQLLine konsole
sqlline.py ir Python skripts, kas iedarbina konsoli, kas izveido savienojumu ar HBase Zookeeper adresi; vietējais saimnieks šajā gadījumā. Šeit varat aplūkot piemēru, kuru es apkopošu šajā sadaļā.
Vispirms apskatīsim visas HBase tabulas, izpildot !tabula:
0: jdbc: phoenix: localhost>! Tabulas + --------------------------------------- --- + ------------------------------------------ + --- --------------------------------------- + ---------- -------------------------------- + ----------------- --------- + | TABLE_CAT | TABLE_SCHEM | TABLE_NAME | TABLE_TYPE | PIEZĪMES | + ------------------------------------------ + ------ ------------------------------------ + ------------- ----------------------------- + -------------------- ---------------------- + -------------------------- + | | SISTĒMA | KATALOGS | SISTĒMAS TABULA | | | SISTĒMA | FUNKCIJA | SISTĒMAS TABULA | | | SISTĒMA | Secība | SISTĒMAS TABULA | | | SISTĒMA | STATS SISTĒMAS TABULA | + ------------------------------------------ + ------ ------------------------------------ + ------------- ----------------------------- + -------------------- ---------------------- + -------------------------- + Tā kā šis ir jauns HBase gadījums, vienīgās tabulas, kas pastāv, ir sistēmas tabulas. Jūs varat izveidot tabulu, izpildot a izveidot tabulu komanda:
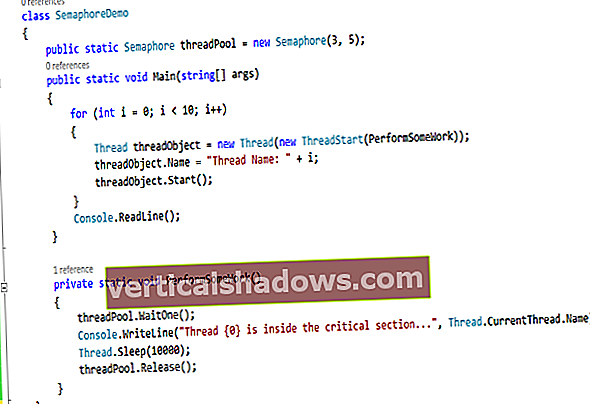
0: jdbc: phoenix: localhost>izveidot tabulas testu (mykey integer nav null primārā atslēga, mycolumn varchar); Nav ietekmētas rindas (2,448 sekundes) Šī komanda izveido tabulu ar nosaukumu pārbaude, ar vesela skaitļa primāro atslēgu nosaukta mykey un a varchar kolonna nosaukta mycolumn. Tagad ievietojiet pāris rindas, izmantojot uz augšu komanda:
0: jdbc: phoenix: localhost>ievadiet testa vērtības (1, “Sveiki”); Ietekmēta 1 rinda (0,142 sekundes) 0: jdbc: phoenix: localhost>iekļaujiet testa vērtībās (2, “Pasaule!”); Ietekmēta 1 rinda (0,008 sekundes) UPSERT ir SQL komanda ieraksta ievietošanai, ja tāda nav, vai atjaunina ierakstu, ja tā ir. Šajā gadījumā mēs ievietojām (1, “Labdien”) un (2, “Pasaule!”). Šeit varat atrast pilnu Phoenix komandas atsauci. Visbeidzot, vaicājiet savai tabulai, lai redzētu vērtības, kuras esat izpildījis, izpildot atlasiet * no testa:
0: jdbc: phoenix: localhost>atlasīt * no testa; + ------------------------------------------ + ------ ------------------------------------ + | MYKEY | MYCOLUMN | + ------------------------------------------ + ------ ------------------------------------ + | 1 | Sveiki | | 2 | Pasaule! | + ------------------------------------------ + ------ ------------------------------------ + 2 atlasītas rindas (0,111 sekundes) Kā paredzēts, redzēsiet tikko ievietotās vērtības. Ja vēlaties sakopt galdu, izpildiet a pilienu galda pārbaude komandu.