Šī raksta nolūkos es pieņemu, ka jūs zināt, kas ir JavaServer Pages (JSP) un paplašināmās iezīmēšanas valoda (XML), taču jums var būt nedaudz neskaidrība par to, kā jūs tos varat izmantot. JSP izmantošanu ir diezgan viegli aizstāvēt. Tas ļauj jums izveidot vietni, kas veidota no failiem, kas izskatās un darbojas daudz kā HTML. Vienīgā atšķirība ir tāda, ka arī JSP darbojas dinamiski - piemēram, viņi var apstrādāt veidlapas vai lasīt datu bāzes - izmantojot Java kā servera puses skriptu valodu. XML lietošanu ir grūtāk pamatot. Lai gan šķiet, ka katrs jauns produkts to atbalsta, šķiet, ka katrs no tiem XML izmanto citam mērķim.
Šajā rakstā jūs uzzināsiet, kā diezgan pieticīgi izstrādāt sistēmu, izmantojot XML. Daudzās vietnēs ir plašas datu kolekcijas, kas tiek parādītas vairāk vai mazāk standarta veidā. Es izveidošu sistēmu, kas izmanto XML failus, lai datus glabātu Web serverī, un JSP failus, lai parādītu šos datus.
XML pret relāciju datu bāzēm
"Bet pagaidiet," jūs varat jautāt, "vai datu glabāšanai izmantojat XML? Kāpēc neizmantot datu bāzi?" Labs jautājums. Atbilde ir tāda, ka daudziem mērķiem datu bāze ir pārspīlēta. Lai izmantotu datu bāzi, jums jāinstalē un jāatbalsta atsevišķs servera process, kas bieži prasa arī datu bāzes administratora instalēšanu un atbalstu. Jums jāapgūst SQL un jāraksta SQL vaicājumi, kas pārveido datus no relācijas uz objekta struktūru un atkal atpakaļ. Ja datus glabājat kā XML failus, jūs zaudējat papildu servera pieskaitāmās izmaksas. Jūs iegūstat arī vienkāršu datu rediģēšanas veidu: vienkārši izmantojiet teksta redaktoru, nevis sarežģītu datu bāzes rīku. XML failus ir arī vieglāk dublēt, koplietot ar draugiem vai lejupielādēt klientiem. Varat arī viegli augšupielādēt jaunus datus savā vietnē, izmantojot FTP.
Abstraktāka XML priekšrocība ir tā, ka, tā kā tas ir hierarhisks, nevis relāciju formāts, to var daudz vienkāršāk izmantot, lai noformētu jūsu vajadzībām atbilstošas datu struktūras. Jums nav jāizmanto entītiju attiecību redaktors, kā arī nav jā normalizē shēma. Ja jums ir viens elements, kas satur citu elementu, varat to attēlot tieši formātā, nevis izmantot pievienošanās tabulu.
Ņemiet vērā, ka daudzām lietojumprogrammām nepietiek ar failu sistēmu. Ja jums ir daudz atjauninājumu, failu sistēma var tikt sajaukta vai sabojāta, vienlaikus rakstot; datubāzes parasti atbalsta darījumus, kas ļauj vienlaicīgi rīkoties bez korupcijas. Turklāt datu bāze ir lielisks rīks, ja jums ir nepieciešams veikt sarežģītus jautājumus, it īpaši, ja tie laiku pa laikam atšķiras. Datu bāzes veido indeksus un ir optimizētas, lai indeksus atjauninātu ar pastāvīgi mainīgo datu kopu. Relāciju datu bāzēm ir arī daudzas citas priekšrocības, tostarp bagātīga vaicājumu valoda, nobrieduši autoru un shēmu noformēšanas rīki, pārbaudīta mērogojamība, detalizēta piekļuves kontrole utt.
(Piezīme. Lai nodrošinātu nabadzīga cilvēka darījumu serveri, varat izmantot vienkāršu failu bloķēšanu. Varat arī Java ieviest XML indeksēšanas un meklēšanas rīku, taču tā ir cita raksta tēma.)
Šajā gadījumā, tāpat kā lielākajā daļā ar zemu un vidēju apjomu, uz publicēšanu balstītu vietņu, var pieņemt, ka: lielākā daļa piekļuves datiem tiek lasīta, nevis rakstīta; lai arī dati, iespējams, ir lieli, tomēr salīdzinoši nemainās; jums nebūs jāveic sarežģīti meklējumi, bet, ja jūs to darīsit, izmantosiet atsevišķu meklētājprogrammu. Nobriedušas RDBMS izmantošanas priekšrocības izzūd, savukārt priekšplānā izvirzās objektorientētā datu modeļa izmantošanas priekšrocības.
Visbeidzot, ir pilnīgi iespējams savai datu bāzei nodrošināt iesaiņotāju, kas veic SQL vaicājumus un pārveido tos XML plūsmās, lai jūs to varētu izmantot abos veidos. XML kļūst par izturīgāku, programmētājiem draudzīgāku priekšgalu nobriedušai datu bāzei glabāšanai un meklēšanai. (Viens no šīs tehnikas piemēriem ir Oracle XSQL servletīkls.)
Lietojumprogramma: tiešsaistes fotoalbums
Fotogrāfijas patīk visiem! Cilvēkiem patīk rādīt savus, savu draugu, savu mājdzīvnieku un atvaļinājumu attēlus. Tīkls ir galvenais līdzeklis pašnodarbināto aizvara kļūdu izplatīšanai - viņi var kaitināt savus radiniekus tūkstošiem jūdžu attālumā. Lai gan pilnvērtīgai fotoalbumu vietnei būtu nepieciešams sarežģīts objekta modelis, es koncentrēšos uz viena definēšanu Bilde objekts. (Šīs lietojumprogrammas avota kods ir pieejams resursos.) Objektam, kas attēlo attēlu, ir nepieciešami lauki, kas apzīmē tā nosaukumu, uzņemšanas datumu, neobligātu parakstu un, protams, norādi uz attēla avotu.
Attēlam savukārt ir nepieciešami daži atsevišķi lauki: avota faila atrašanās vieta (GIF vai JPEG), kā arī augstums un platums pikseļos (lai palīdzētu veidot
Visbeidzot, paplašināsim attēlu ierakstu ar elementu, kas nosaka sīktēlu kopu lietošanai satura rādītājā vai citur. Šeit es izmantoju to pašu jēdzienu attēls Es jau iepriekš definēju.
Attēla XML attēlojums varētu izskatīties šādi:
Alekss pludmalē 1999-08-08 veltīgi cenšas iegūt iedegumu alex-beach.jpg 340 200 alex-beach-sm.jpg 72 72 alex-beach-med.jpg 150 99
Ņemiet vērā, ka, izmantojot XML, visa informācija par vienu attēlu tiek ievietota vienā failā, nevis izkaisīta starp trim vai četrām atsevišķām tabulām. Sauksim to par .pix fails - tātad jūsu failu sistēma varētu izskatīties šādi:
summer99 / alex-beach.pix summer99 / alex-beach.jpg summer99 / alex-beach-sm.jpg summer99 / alex-beach-med.jpg summer99 / alex-snorkelēšana.pix u.c.
Tehnika
Ir vairāk nekā viens veids, kā nodzīt kaķim ādu, un ir vairāki veidi, kā XML datus pārnest uz jūsu JSP lapu. Šeit ir saraksts ar dažiem no šiem veidiem. (Šis saraksts nav pilnīgs; daudzi citi produkti un ietvari kalpotu vienlīdz labi.)
- DOM: XML faila parsēšanai un pārbaudei varat izmantot klases, kas ievieš DOM saskarni
- XMLEntryList: Jūs varat izmantot manu kodu, lai XML ielādētu
java.util.Listno vārdu un vērtību pāriem - XPath: Lai atrastu elementus XML failā pēc ceļa nosaukuma, varat izmantot XPath procesoru (piemēram, sveķus)
- XSL: XML pārveidošanai HTML formātā varat izmantot XSL procesoru
- Kokons: Jūs varat izmantot atvērtā koda kokonu sistēmu
- Rullējiet savu pupiņu: Jūs varat rakstīt iesaiņošanas klasi, kas izmanto kādu no citiem paņēmieniem, lai datus ielādētu pielāgotā JavaBean
Ņemiet vērā, ka šīs metodes vienlīdz labi var piemērot XML straumei, kuru saņemat no cita avota, piemēram, klienta vai lietojumprogrammu servera.
JavaServer lapas
JSP spec ir bijis daudz iemiesojumu, un dažādi JSP produkti ievieš dažādas, nesaderīgas spec versijas. Es izmantošu Tomcat šādu iemeslu dēļ:
- Tas atbalsta visjaunākās JSP versijas un servletu specifikācijas
- To apstiprina Saule un Apache
- To var palaist patstāvīgi, nekonfigurējot atsevišķu tīmekļa serveri
- Tas ir atvērtā koda
(Lai iegūtu vairāk informācijas par Tomcat, skatiet resursus.)
Laipni lūdzam izmantot jebkuru jums patīkamu JSP dzinēju, taču tā konfigurēšana ir jūsu ziņā! Pārliecinieties, ka motors atbalsta vismaz JSP 1.0 spec; no 0.91 līdz 1.0 bija daudz izmaiņu. JSWDK (Java Server Web Development Kit) darbosies lieliski.
JSP struktūra
Veidojot JSP vadītu vietni (pazīstama arī kā a Tīmekļa lietotne), Es gribētu kopīgās funkcijas, importēšanu, konstantes un mainīgo deklarācijas ievietot atsevišķā failā ar nosaukumu init.jsp, kas atrodas šī raksta avota kodā.
Pēc tam es ielādēju šo failu katrā JSP failā, izmantojot . The direktīva darbojas tāpat kā C valoda # iekļaut, ievelkot iekļautā faila tekstu (šeit, init.jsp) un sastādot tā, it kā tā būtu daļa no faila (šeit, bilde.jsp). Turpretī tag kompilē failu kā atsevišķu JSP failu un iekļauj tajā izsaukumu kompilētajā JSP.
Faila atrašana
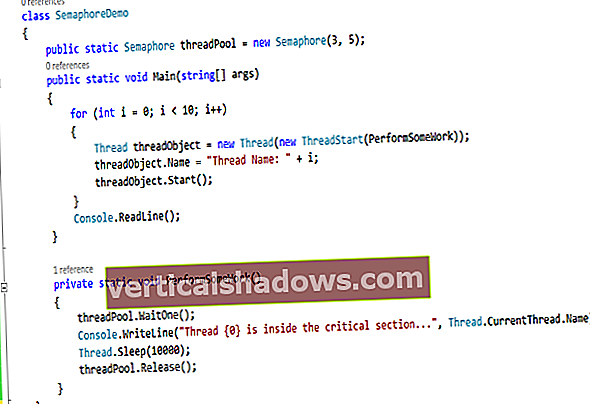
Kad sākas JSP, pirmā lieta, kas tai jādara pēc inicializācijas, ir vajadzīgā XML faila atrašana. Kā tā zina, kurš no daudzajiem failiem jums ir nepieciešams? Atbilde ir no CGI parametra. Lietotājs izsauks JSP ar URL picture.jsp? file = summer99 / alex-beach.pix (vai izlaižot a failu izmantojot HTML veidlapu).
Tomēr, kad JSP saņem parametru, jūs joprojām esat tikai pusceļā. Jums joprojām jāzina, kur atrodas failu sistēmā saknes direktorijs. Piemēram, Unix sistēmā faktiskais fails var būt direktorijā /home/alex/public_html/pictures/summer99/alex-beach.pix. JSP izpildīšanas laikā nav pašreizējā direktorija jēdziena, tāpēc jums jānorāda absolūts ceļa nosaukums java.io iepakojums.
Serversīklietotnes API nodrošina metodi, kā URL ceļu salīdzinājumā ar pašreizējo JSP vai Servletu pārvērst par absolūtu failu sistēmas ceļu. Metode ServletContext.getRealPath (virkne) izdara triku. Katram JSP ir ServletKonteksts objekts sauc pieteikumu, tāpēc kods būtu:
Virkne picturefile = application.getRealPath ("/" + pieprasījums.getParameter ("fails")); vai
Virknes picturefile = getServletContext (). GetRealPath ("/" + pieprasījums.getParameter ("fails")); kas darbojas arī servleta iekšpusē. (Jums jāpievieno a / jo metode paredz, ka tiks nodoti request.getPathInfo ().)
Viena svarīga piezīme: ikreiz, kad piekļūstat vietējiem resursiem, esiet ļoti uzmanīgs, lai apstiprinātu ienākošos datus. Hakeris vai neuzmanīgs lietotājs var nosūtīt viltus datus, lai uzlauztu jūsu vietni. Piemēram, apsveriet, kas notiktu, ja vērtība fails = .. / .. / .. / .. / etc / passwd tika ievadīti. Šādā veidā lietotājs varēja izlasīt jūsu servera paroles failu.
Dokumenta objekta modelis
DOM apzīmē Dokumenta objekta modelis. Tas ir standarta API XML dokumentu pārlūkošanai, ko izstrādājis World Wide Web Consortium (W3C). Saskarnes ir iepakojumā org.w3c.dom un tiek dokumentēti W3C vietnē (skatīt resursus).
Ir pieejamas daudzas DOM parsētāja realizācijas. Es izvēlējos IBM XML4J, taču jūs varat izmantot jebkuru DOM parsētāju. Tas ir tāpēc, ka DOM ir saskarņu kopa, nevis klases - un visiem DOM parsētājiem ir jāatgriež objekti, kas uzticīgi ievieš šīs saskarnes.
Diemžēl, kaut arī standarta, DOM ir divi galvenie trūkumi:
- Lai arī API ir orientēta uz objektu, tā ir diezgan apgrūtinoša.
- DOM parsētājam nav standarta API, tāpēc, kamēr katrs parsētājs atgriež a
org.w3c.dom.Documentobjekts, parsētāja inicializācijas un faila ielādes līdzekļi vienmēr ir specifiski parsētājam.
Iepriekš aprakstīto vienkāršo attēlu failu DOM attēlo vairāki objekti koka struktūrā.
Dokumenta mezgls -> Elementa mezgls "picture" -> Teksta mezgls "\ n" (atstarpe) -> Elementa mezgla "nosaukums" -> Teksta mezgls "Alex On The Beach" -> Elementa mezgls "date" - -> ... utt.
Lai iegūtu vērtību Alekss Pludmalē jums vajadzētu veikt vairākus metodes izsaukumus, ejot pa DOM koku. Turklāt parsētājs var izvēlēties sakrustot jebkuru atstarpes teksta mezglu skaitu, caur kuriem jums būtu jāveic cilpa un vai nu jāignorē, vai arī jāapvieno (to var izlabot, izsaucot normalizēt () metode). Parsētājs var iekļaut arī atsevišķus mezglus XML entītijām (piemēram, &), CDATA mezglus vai citus elementu mezglus (piemēram, liels lācis pārvērstos vismaz par trim mezgliem, no kuriem viens ir a b elements, kas satur teksta mezglu, kurā ir teksts liels). DOM nav metodes, kā vienkārši pateikt "iegūt virsraksta elementa teksta vērtību". Īsāk sakot, staigāt pa DOM ir mazliet apgrūtinoši. (Alternatīvu DOM skatiet šī raksta sadaļā XPath.)
No augstākas perspektīvas DOM problēma ir tā, ka XML objekti nav pieejami tieši kā Java objekti, bet tiem ir jāpieiet pa daļām, izmantojot DOM API. Skatiet manu secinājumu par Java-XML Data Binding tehnoloģijas diskusiju, kas izmanto šo tieši Java pieeja, lai piekļūtu XML datiem.
Esmu uzrakstījis nelielu lietderības klasi, sauktu DOMlietotāji, kas satur statiskas metodes kopīgu DOM uzdevumu veikšanai. Piemēram, lai iegūtu teksta saturu nosaukums saknes bērns elements (bilde), jūs uzrakstīsit šādu kodu:
Dokuments doc = DOMUtils.xml4jParse (picturefile); Elementa mezglsRoot = doc.getDocumentElement (); Mezgls nodeTitle = DOMUtils.getChild (nodeRoot, "nosaukums"); Virknes nosaukums = (nodeTitle == null)? null: DOMUtils.getTextValue (nodeTitle);
Attēlu apakšelementu vērtību iegūšana ir vienlīdz vienkārša:
Mezgls nodeImage = DOMUtils.getChild (nodeRoot, "attēls"); Mezgls nodeSrc = DOMUtils.getChild (nodeImage, "src"); String src = DOMUtils.getTextValue (nodeSrc);
Un tā tālāk.
Kad katram attiecīgajam elementam ir Java mainīgie, viss, kas jums jādara, ir iegult mainīgos HTML marķējumā, izmantojot standarta JSP tagus.
Plašāku informāciju skatiet pilnā pirmkodā. JSP faila izveidotā HTML izeja - HTML ekrānuzņēmums, ja vēlaties - atrodas picture-dom.html.