R data.table kods kļūst efektīvāks un elegants, kad izmantojat tā īpašos simbolus un funkcijas. Paturot to prātā, mēs izskatīsim dažus īpašus veidus, kā apakškopas, uzskaitīt un izveidot jaunas kolonnas.
Šajā demonstrācijā es izmantošu datus no 2019. gada Stack Overflow izstrādātāju aptaujas ar aptuveni 90 000 atbildēm. Ja vēlaties sekot līdzi, datus varat lejupielādēt no kaudzes pārpildes.
Ja jūsu sistēmā nav instalēta pakete data.table, instalējiet to no CRAN un pēc tam ielādējiet to kā parasti bibliotēka (data.table). Lai sāktu, ieteicams izlasīt tikai dažas pirmās datu kopas rindas, lai būtu vieglāk izpētīt datu struktūru. To var izdarīt, izmantojot datu.tabulas maize () funkcija un nrows arguments. Es lasīšu 10 rindās:
datu_paraugs <- fread ("dati / aptaujas_rezultāti_publika.csv", nrows = 10)Kā redzēsit, ir jāpārbauda 85 slejas. (Ja vēlaties uzzināt, ko nozīmē visas kolonnas, lejupielādētajā failā ir faili ar sākotnējās aptaujas datu shēmu un PDF failu.)
Lai izlasītu visus datus, es izmantoju:
mydt <- fread ("data / survey_results_public.csv")Pēc tam es izveidošu jaunu datu tabulu ar tikai dažām kolonnām, lai būtu vieglāk strādāt un redzēt rezultātus. Atgādinājums, ka data.table izmanto šo pamata sintaksi:
mydt [i, j, autors]
Paketes data.table ievadā teikts, ka tas jālasa kā “paņemiet dt, apakškopu vai pārkārtojiet rindas, izmantojot i, aprēķiniet j, grupējot pēc. Paturiet prātā, ka i un j ir līdzīgi bāzes R iekavu secībai: rindas pirmās, kolonnas otrās. Tātad es domāju operācijām, kuras veicat rindās (izvēloties rindas, pamatojoties uz rindu numuriem vai nosacījumiem); j ir tas, ko jūs darītu ar kolonnām (atlasiet kolonnas vai izveidojiet jaunas kolonnas no aprēķiniem). Tomēr ņemiet vērā arī to, ka jūs varat izdarīt daudz vairāk iekšējo datu. Tabulas iekavās nekā pamata R datu rāmī. Un sadaļa “līdz” ir jauna data.table.
Tā kā esmu atlasot kolonnās šis kods atrodas “j” vietā, kas nozīmē, ka iekavās vispirms ir nepieciešams komats, lai atstātu “i” vietu tukšu:
mydt [, j]
Atlasiet datu.tabulas kolonnas
Viena no lietām, kas man patīk par datu.tabulu, ir tā, ka kolonnas ir viegli atlasīt vai nu citēts, vai nekotēts. Nekotēts bieži ir ērtāk (tas parasti ir kārtīgs veids). Bet citēts ir noderīga, ja izmantojat datu.tabulu pašu funkciju iekšienē vai ja vēlaties nodot vektoru, kuru savā kodā izveidojāt kaut kur citur.
Jūs varat atlasīt data.table kolonnas parastajā bāzes R veidā, izmantojot parasto kotēto kolonnu nosaukumu vektoru. Piemēram:
dt1 <- mydt [, c ("LanguageWorkedWith", "LanguageDesireNextYear","OpenSourcer", "CurrencySymbol", "ConvertedComp",
“Hobists”)]
Ja vēlaties tos izmantot uncitēts, izveido a sarakstā a vietā vektors un jūs varat ievadīt citātus, kas nav citēti.
dt1 <- mydt [, saraksts (LanguageWorkedWith, LanguageDesireNextYear,OpenSourcer, CurrencySymbol, ConvertedComp,
Hobijs)]
Un tagad mēs nonākam pie sava pirmā īpašā simbola. Tā vietā, lai ierakstītu saraksts (), varat vienkārši izmantot punktu:
dt1 <- mydt [,. (LanguageWorkedWith, LanguageDesireNextYear,OpenSourcer, CurrencySymbol, ConvertedComp,
Hobijs)]
Tas .() ir saīsne domēnam saraksts () iekšējie dati.tabulas iekavas.
Ko darīt, ja vēlaties izmantot jau esošu kolonnu nosaukumu vektoru? Vektora objekta nosaukuma ievietošana data.table iekavās nedarbosies. Ja izveidoju vektoru ar citētiem kolonnu nosaukumiem, piemēram:
mycols <- c ("LanguageWorkedWith", "LanguageDesireNextYear","OpenSourcer", "CurrencySymbol", "ConvertedComp", "Hobbyist")
Tad šis kods būsnē darbs:
dt1 <- mydt [, mikoli]
Tā vietā jums ir jāliek .. (tas ir divi punkti) vektora objekta nosaukuma priekšā:
dt1 <- mydt [, ..mycols]
Kāpēc divi punkti? Tas man likās kaut kā nejauši, līdz es izlasīju skaidrojumu. Padomājiet par to tāpat kā divi punkti Unix komandrindas terminālā, kas pārvieto jūs vienā direktorijā. Lūk, jūs virzāties augšup pa vienu nosaukumvieta, no vides datu.tabulas iekavās līdz pat globālajai videi. (Tas tiešām palīdz man to atcerēties!)
Count data.table rindas
Tālāk uz nākamo simbolu. Lai skaitītu pēc grupas, varat izmantot datus.table’s .N simbols, kur.N apzīmē rindu skaitu. Tas var būt kopējais rindu skaits vai rindu skaits katrai grupai ja apkopojat sadaļā “pēc”.
Šī izteiksme atgriež kopējo rindu skaitu data.table:
mydt [, .N]
Šis piemērs aprēķina rindu skaitu, kas sagrupētas pēc viena mainīgā: vai cilvēki aptaujā kodē arī kā hobiju ( Hobijs mainīgais).
mydt [, .N, hobijs]# atgriež:
Hobijs N 1: jā 71257 2: nē 17626
Ja ir tikai viens mainīgais, data.table iekavās varat izmantot vienkāršo kolonnas nosaukumu. Ja vēlaties grupēt pēc diviem vai vairākiem mainīgajiem, izmantojiet . simbols. Piemēram:
mydt [, .N,. (hobijs, OpenSourcer)]
Lai pasūtītu rezultātus no augstākā līdz zemākajam, pēc pirmā varat pievienot otro iekavu kopu. The .N simbols automātiski ģenerē kolonnu ar nosaukumu N (protams, varat to pārdēvēt, ja vēlaties), tāpēc pasūtīšana pēc rindu skaita var izskatīties šādi:
mydt [, .N,. (Hobbyist, OpenSourcer)] [pasūtījums (Hobbyist, -N)]
Mācoties data.table kodu, man ir noderīgi to lasīt soli pa solim. Tāpēc es to izlasīju kā “Par visi rindas mydt (tā kā “I” vietā nekā nav), saskaitiet rindu skaitu, grupējot pēc Hobbyist un OpenSourcer. Pēc tam vispirms pasūtiet Hobbyist un pēc tam samazinās rindu skaits. ”
Tas ir līdzvērtīgs šim dplyr kodam:
mydf%>%skaits (hobijs, OpenSourcer)%>%
pasūtījums (hobijs, -n)
Ja jums šķiet, ka tidyverse parastā daudzrindu pieeja ir lasāmāka, darbojas arī šis data.table kods:
mydt [, .N,(Hobijs, OpenSourcer)] [
pasūtījums (hobijs, -N)
]
Pievienojiet slejas datu tabulai
Pēc tam es vēlētos pievienot slejas, lai redzētu, vai katrs respondents izmanto R, vai viņi izmanto Python, vai viņi izmanto abus vai nevienu no tiem. The ValodaDarbojās ar kolonnā ir informācija par izmantotajām valodām, un dažas šo datu rindas izskatās šādi:
 Šarona Mačlisa
Šarona Mačlisa Katra atbilde ir viena rakstzīmju virkne. Lielākajai daļai valodu ir vairākas, atdalot tās ar semikolu.
Kā tas bieži notiek, meklēt Python ir vieglāk nekā R, jo jūs nevarat vienkārši meklēt virknē "R" (Ruby un Rust satur arī lielo R), kā jūs varat meklēt "Python". Šis ir vienkāršāks kods, lai izveidotu TRUE / FALSE vektoru, kas pārbauda, vai katra virkne ir ValodaDarbojās ar satur Python:
ifelse (LanguageWorkedWith%, piemēram,% "Python", TRUE, FALSE)
Ja jūs zināt SQL, jūs atpazīsit šo līdzīgo sintaksi. Man, labi, patīk % patīk%. Tas ir jauks vienkāršots veids, kā pārbaudīt modeļu atbilstību. Funkcijas dokumentācijā teikts, ka tā ir paredzēta lietošanai data.table iekavās, taču patiesībā jūs to varat izmantot jebkurā kodā, ne tikai ar data.tables. Es pārbaudīju ar data.table autors Matt Dowle, kurš teica, ka padoms to izmantot iekavās ir tāpēc, ka tur notiek papildu veiktspējas optimizācija.
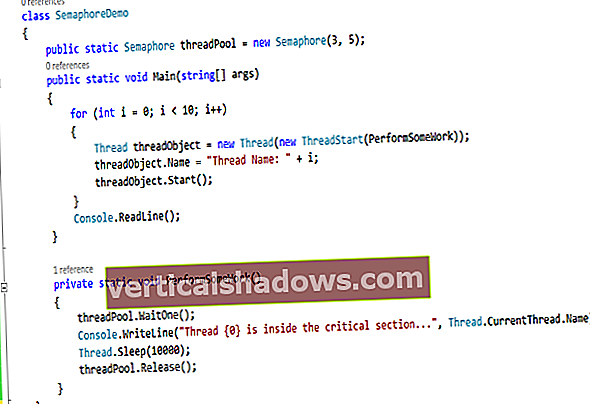
Pēc tam šeit ir kods, lai pievienotu kolonnu ar nosaukumu PythonUser tabulā data.table:
dt1 [, PythonUser: = ifelse (LanguageWorkedWith%, piemēram,% "Python", TRUE, FALSE)]
Ievērojiet := operators. Arī Python ir tāds operators, un kopš tā laika, kad dzirdēju, ka to sauc par “valzirgu operatoru”, es to arī saucu. Es domāju, ka tas ir oficiāli “norīkojums pēc atsauces”. Tas ir tāpēc, ka iepriekš minētais kods mainīja esošo objekta dt1 data.table, pievienojot jaunu kolonnu - bez nepieciešams to saglabāt jaunā mainīgajā.
Lai meklētu R, es izmantošu regulāro izteiksmi "\ bR \ b" kas saka: “Atrodiet modeli, kas sākas ar vārdu robežu - \ b, pēc tam Run pēc tam noslēdziet ar citu vārdu robežu. (Es nevaru meklēt tikai "R;", jo katras virknes pēdējam vienumam nav semikola.)
Tādējādi dt1 kolonnai RUser tiek pievienots:
dt1 [, RUser: = ifelse (LanguageWorkedWith% like% "\ bR \ b", TRUE, FALSE)]
Ja vēlaties pievienot abas kolonnas vienlaikus ar := jums vajadzētu pārvērst šo valzirgu operatoru par funkciju, citējot to atpakaļ, šādi:
dt1 [, `:=`(PythonUser = ifelse (LanguageWorkedWith%, piemēram,% "Python", TRUE, FALSE),
RUser = ifelse (LanguageWorkedWith%, piemēram,% "\ bR \ b", TRUE, FALSE)
)]
Noderīgāki dati.tabulu operatori
Ir vairāki citi dati. Galda operatori, kurus vērts zināt. The%starp% operatoram ir šāda sintakse:
myvector% starp% c (zemākā_vērtība, augšējā_vērtība)
Tātad, ja es vēlos filtrēt visas atbildes, kurās kompensācija bija no 50 000 līdz 100 000, kas maksāta ASV dolāros, šis kods darbojas:
comp_50_100k <- dt1 [CurrencySymbol == "USD" &ConvertedComp% starp% c (50000, 100000)]
Otrā augšējā rinda ir starp nosacījumu. Ņemiet vērā, ka %starp% operators, pārbaudot, iekļauj gan apakšējo, gan augšējo vērtību.
Vēl viens noderīgs operators ir % zods%. Tas darbojas kā bāzes R %% bet ir optimizēts ātrumam un ir paredzēts tikai rakstzīmju vektori. Tātad, ja es vēlos filtrēt visas rindas, kurās OpenSourcer sleja bija “Nekad” vai “Mazāk kā reizi gadā”, šis kods darbojas:
reti - <- dt1 [OpenSourcer% chin% c ("Nekad", "Mazāk kā reizi gadā")]Tas ir diezgan līdzīgs bāzei R, izņemot to, ka bāzei R iekavas iekšpusē ir jānorāda datu rāmja nosaukums un pēc filtra izteiksmes ir nepieciešams arī komats:
raros_df <- df1 [df1 $ OpenSourcer%% c ("Nekad", "Mazāk kā reizi gadā"),]Jaunā fcase () funkcija
Šajā pēdējā demonstrācijā es sākšu, izveidojot jaunu datu tabulu, kurā ir tikai cilvēki, kuri ziņoja par kompensāciju ASV dolāros:
usd <- dt1 [CurrencySymbol == "USD" &! is.na (ConvertedComp)]
Pēc tam es izveidošu jaunu sleju ar nosaukumu Valoda vai kāds izmanto tikai R, tikai Python, abus vai nevienu. Es izmantošu jauno fcase () funkciju. Laikā, kad šis raksts tika publicēts, fcase () bija pieejams tikai datu.tabulas izstrādes versijā. Ja jums jau ir instalēta data.table, varat atjaunināt uz jaunāko dev versiju, izmantojot šo komandu:
data.table :: update.dev.pkg ()
Funkcija fcase () ir līdzīga SQL LIETAS KAD paziņojums un dplyr's case_when () funkciju. Pamata sintakse irfcase (nosacījums1, "vērtība1", nosacījums2, "vērtība2") un tā tālāk. Noklusējuma vērtību “viss pārējais” var pievienot, izmantojot noklusējums = vērtība.
Šeit ir kods, lai izveidotu jauno kolonnu Valoda:
usd [, valoda: = fcase (RUser &! PythonUser, "R",
PythonUser &! RUser, "Python",
PythonUser un RUser, "abi",
! PythonUser &! RUser, "Ne"
)]
Es ievietoju katru nosacījumu atsevišķā rindā, jo man ir vieglāk lasīt, bet jums tas nav jādara.
Brīdinājums: ja izmantojat RStudio, pēc tam, kad esat izveidojis jaunu kolonnu ar valzirgu operatoru, RStudio rūts augšējā labajā stūrī dati automātiski netiek atjaunināti. Jums ir manuāli jānoklikšķina uz atsvaidzināšanas ikonas, lai redzētu izmaiņas kolonnu skaitā.
Ir daži citi simboli, kurus es neaptvēršu šajā rakstā. To sarakstu var atrast palīgfailā “Īpašie simboli” data.table palīdzības failā palīdzība ("īpašie simboli"). Vienam no visnoderīgākajiem .SD jau ir savs Do More With R raksts un videoklips “Kā izmantot .SD paketē R data.table”.
Lai iegūtu vairāk R padomu, dodieties uz “Do More With R” lapu vai skatiet YouTube atskaņošanas sarakstu “Do More With R”.